Parsing with XLE
There are three key ideas that XLE uses to make its parser efficient:
The first idea is to pay careful attention to the interface between phrasal and functional constraints. In particular, XLE processes all of the phrasal constraints first using a chart, and then using the result to decide which functional constraints to process. This is more efficient than interleaving phrasal and functional constraints since the phrasal constraints can be processed in cubic time, whereas the functional constraints may take exponential time. Thus, the phrasal constraints make a good polynomial filter for the functional constraints.
The second key idea is to use contexted unification to merge multiple feature structures together into a single, packed feature structure. This approach allows to handle ambiguity by preserving all possible representations – and interpretations – for one single sentence. Further information on ambiguity management can be found here.
The third key idea is to use lazy contexted copying during unification. Lazy contexted unification only copies up as much of the two daughter feature structures of a subtree as is needed to determine whether the feature structures are unifiable. If the interaction between the daughter feature structures are bounded, then XLE will do a bounded amount of work per subtree. Since there are at most a cubic number of subtrees in the chart, then XLE can parse sentences in cubic time when the interactions between daughter feature structures are bounded.
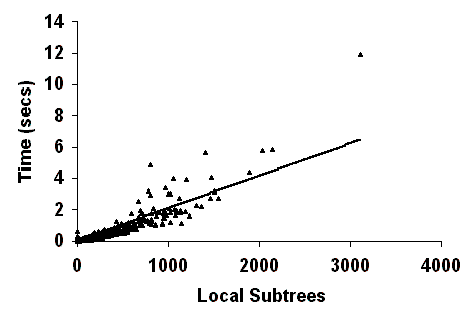
Here is a scatterplot of XLE applied to a corpus of sentences from the documentation of the HomeCentre, a multi-function copier/printer device marketed by Xerox. Each sentence is plotted according to the number of local subtrees that it has (on the x-axis) and the time that it takes to parse the sentence (on the y-axis). If the time grows linearly in the number of subtrees, then this means that a bounded amount of work is being done per subtree and so XLE is parsing in cubic time. By doing a linear regression we find that 79 percent of the time can be explained by the number of subtrees in this corpus. The data points that are higher than expected correspond to sentences that have a lot of coordination and/or long-distance dependencies. These constructions require a lot of the feature structure to be copied up, and so they increase the effective grammar constant.
At last, XLE uses to strategies to ensure robustness in the face of ill-formed inputs and shortfalls in the coverage of the grammar. You can find more information on this topic here.