Copyright © 1993-2001 by the Xerox Corporation and Copyright © 2002-2005 by the Palo Alto Research Center. All rights reserved.
XLE is a computational environment that assists in writing and debugging Lexical Functional Grammars (LFGs) (Kaplan & Bresnan, 1982). It provides linguists with a facility for writing syntactic rules and lexical entries, and for testing and editing them. It also provides an interface with finite-state morphological analyzers. The system applies these specifications to sentences or other strings and then provides the following analytic information:
XLE was originally written in the 1990's and implements some of the recent additions to the LFG formalism. It includes outside-in and inside-out functional uncertainty (Kaplan & Zaenen, 1989), distribution over sets, restriction, and a rich notation for expressing c-structure patterns. The system allows correspondences between multiple levels of linguistic representation to be defined, as described by Kaplan (1987) and Halvorsen and Kaplan (1988). As a simple application of this capability, the system can display the properties of a semantic representation that is characterized and associated with a string by lexical and syntactic schemata. Parameterized macros and templates are supported so that common constituent and functional patterns can be expressed as independent generalizations.
The system provides a powerful interface for defining and manipulating linguistic rules and representations. After installing a collection of syntactic rules and lexical entries into XLE, you can see whether those items are sufficient to analyze sentences or phrases in the language in question. You can also easily mix and match different sets of linguistic specifications as you experiment with different versions of particular rules and lexical entries, whether you have written them yourself or they have been provided by other users of the system.
XLE also supports other activities that surround the business of grammar development. These include: analyzing performance, processing testsuites, and saving analyses in a number of formats (postscript, prolog, and LFG lexical entries).
XLE is implemented in C, and runs on Solaris, linux, and MacOSX. XLE and this document try to be self-contained, so that a linguist can successfully use the system without detailed knowledge of the programming environment, although a basic knowledge of the emacs editor will be assumed (for an emacs tutorial type "C-h t" within emacs).
The first section of this document is tutorial in nature. It guides you through the process of entering a new grammar into XLE. It also describes how to use the system to parse sentences or other strings and to evaluate and edit your linguistic descriptions. It assumes some familiarity with the operating system (including window and mouse manipulation), the Emacs text-editor, and the linguistic principles of Lexical Functional Grammar. To use this tutorial, you will need to install lfg-mode.el in your Emacs. See the documentation in the XLE User's Manual for more details.
If you follow through this tutorial, you will enter a grammar that can analyze simple sentences such as The girl walks. Not very impressive, but going through that procedure should give you the mechanics you need to enter grammars that are substantially more complex. The second section of this document continues the tutorial with a more complicated grammar, showing in more detail how XLE can help you understand the properties of a given grammar and aid you in identifying and correcting its defects; this is the process of grammar debugging. Further documentation provides formal characterizations of the notations used for the various linguistic specifications, and provides reference material on the various windows and menus that are used to interact with the system.
This section presents a tutorial introduction to the procedures for typing in syntactic rules, lexical entries, and morphological rules, the linguistic specifications that are necessary for sentence analysis. It also tells you how to create a new configuration, the repository for information about the rules, lexical entries and other information that make up a consistent sentence analysis environment. We begin with a brief discussion of the tedious but necessary matter of how you must refer to your linguistic specifications once you have entered them into the system.
An LFG grammar may have a variety of different kinds of linguistic specifications within it: c-structure rules, lexical entries, different abbreviatory conventions, and other kinds of specifications that might be introduced as the theory and system evolve. At any one time the grammar may have more than one version of a given rule or lexical entry in it. Only one of them can be active when the system analyzes a sentence, so some mechanism is needed to distinguish between them. The LFG formalism allows the grammar writer to distinguish between different versions of the same rule or lexical entry by giving them different names. The name of an item is composed of three parts: its version, its language, and its item-identifier. Thus, there may be two versions of the S rule, one in TOY ENGLISH and one in STANDARD ENGLISH. The Config File dictates which version takes precedence.
Let's start by entering some syntactic rules for a simple version of English, called TOY ENGLISH.
A grammar minimally consists of two files: a grammar and lexicon file and a morphology. First consider the grammar and lexicon file. In general, this file has the following format:
TOY ENGLISH CONFIG (1.0) ROOTCAT S. FILES . LEXENTRIES (TOY ENGLISH). RULES (TOY ENGLISH). TEMPLATES (TOY ENGLISH). GOVERNABLERELATIONS SUBJ OBJ OBJ2 OBL OBL-?+ COMP XCOMP. SEMANTICFUNCTIONS ADJUNCT TOPIC. NONDISTRIBUTIVES NUM PERS. EPSILON e. OPTIMALITYORDER NOGOOD. ---- TOY ENGLISH RULES (1.0) ---- TOY ENGLISH TEMPLATES (1.0) ---- TOY ENGLISH LEXICON (1.0) ----
Each section begins with a version id, a language id, a component id, and the XLE version number (1.0). Each section is terminated with four dashes (----). Here is an explanation of the different parts:
TOY ENGLISH CONFIG (1.0): TOY is the version of the grammar; ENGLISH is the language; CONFIG states that this is the configuration for the version and grammar; (1.0) is the XLE version number.
ROOTCAT: the default category when parsing; the value here is S (for sentence).
FILES: a list of files to be included; these should always end in .lfg; no file is listed here.
LEXENTRIES: a specification of which lexical entries are given precedence; here (TOY ENGLISH) indicates that the lexical entries in the TOY ENGLISH section are to be used.
RULES: a specification of which rules are given precedence; here (TOY ENGLISH) indicates that the rules in the TOY ENGLISH section are to be used.
TEMPLATES: a specification of which templates are given precedence; here (TOY ENGLISH) indicates that the templates in in the TOY ENGLISH section are to be used.
GOVERNABLERELATIONS: a list of grammatical relations which must be subcategorized for in order to appear, e.g., these obey completeness and coherence.
SEMANTICFUNCTIONS: a list of attributes whose values must contain a PRED.
NONDISTRIBUTIVES: a list of attributes which do not distribute when coordinated.
OPTIMALITYORDER: the ranking of optimality constraints; here no constraints are listed.
At this point create an emacs file called:
In it, type in (or cut and paste from this documentation) exactly the information given above. This will be the main grammar file. The next sections will describe how to enter the rules and templates and then how to create a lexicon file.
Rules are entered into XLE by editing the rule file (toy-eng.lfg for this tutorial). The Version and Language are the two parts of the rule file that were introduced above.
The format for a single simple rule is the following:
Category --> Category1: Schemata1;
Category2: Schemata2;
Etc.
The notation for the rule is closely related to the conventional appearance of LFG rules in published papers, but it includes a little more punctuation so that XLE can clearly understand the different aspects of the rule. (XLE's notation is also more expressive in many ways, as detailed in the documentation on Grammatical Notations.) You might write a simple S rule on paper by putting the schemata under the category, like this:
S --> NP VP
(^ SUBJ)=! ^=!
(^ CASE)=NOM
In this conventional notation, the association between categories and schemata is marked by their spatial arrangement: schemata are written immediately below their associated categories. This two-dimensional layout is difficult to type and also difficult for XLE to interpret. Thus rules are typed into XLE linearly, using punctuation marks to indicate how categories and schemata are grouped:
S --> NP: (^ SUBJ)=! (! CASE)=NOM;
VP: ^=!.
Note that ^ is used for the LFG up-arrow and ! is used for the LFG down-arrow.
In XLE, schemata come after a colon following a category. The punctuation is crucial. The system understands that a schema is attached to the NP only because of the colon which precedes it. The semicolon acts as a close colon; it informs the system that you have finished with the schemata for one category and the next symbol will be a new category. The final period in the rule says, this is the end of the S rule. If anything follows, it must be the beginning of a new rule.' Any string of alphanumeric characters can serve as a category name, and a few punctuation marks such as ' (single-quote) are also allowed. A category name may not contain punctuation marks that are also used as operators in the regular-predicate notation that more complex rules are written in (see the documentation on Grammatical Notations.).
Apart from these system-specific items, the usual paper-and-pencil punctuation for rule-writing is used. The right side of a rule can be a regular expression of category/equation pairs, with parentheses indicating optional elements, Kleene star (*) to say that zero or more repetitions of a regular expression are allowed, vertical bar (|) to separate disjuncts within curly brackets ({,}) surrounding the whole disjunction. Symbols and categories must be separated from each other by white-space, which can be indicated by any number of spaces, carriage-returns, or tabs.
In your toy-eng.lfg file, type a first stab at a rule for Sentence in the rules section, i.e., after TOY ENGLISH RULES (1.0) and before the ---- ending the rules section. Make sure that at least one space or carriage return separates its category from the word ENGLISH:
S --> NP
VP.
The daughter categories, NP and VP, need some schemata. To indicate that the NP is the subject and is in the nominative case, type the following immediately after 'NP':
: (^ SUBJ)=! (! CASE)=NOM;
Don't forget the colon and semicolon. The VP is the head of the S, so it should be followed by:
: ^=!
(This annotation is optional. If there is no equation mentioning ! associated with a category, then XLE assumes that ^=!). Type this in before the period and the rule for S becomes
S --> NP: (^ SUBJ)=!
(! CASE)=NOM;
VP: ^=!.
As mentioned, the semi-colon is used to indicate where the annotations for a particular category end. But it is not needed after the annotations on the VP since the closing period is sufficient to show where the annotations end. Nor is it needed after a simple category name unembellished by a colon and schemata, or where there is some other punctuation mark (such as a Kleene star) that is unmistakably not part of a schema.
The next step is to notify XLE that you have finished formulating the rule, and that the rule should be `installed', that is, loaded into XLE.
Save the file using C-x C-s (the standard Emacs save command). If at any time you want to have the rule nicely formatted, place the cursor in the rule and type M-q (the standard Emacs command for formatting a paragraph which is redefined by lfg-mode.). Using the formatting feature can help to ensure that the rule you typed is a legitimate rule, e.g., that there are enough ; and :.
Let's play around a bit with the rule format. Remove the semicolon after the NOM symbol and type M-q. This is the result:
S --> NP: (^ SUBJ)=!
(! CASE)=NOM
VP: ^=!.
Without the semicolon, the system assumes that what follows NOM is part of a functional schema, not a new category. So it treats each successive item as a designator in the f-description language, and lines the VP up under the NP constraints.
Now, correct the rule by re-inserting the semicolon and then delete the colon after NP. This time XLE prints:
S --> NP: (^ SUBJ)=!
(! CASE)=NOM;
VP: ^=!.
Without the colon in this case, XLE does not interpret what follows NP as a schema. Instead, it is interpreted as a category, and lined up under the NP. You can revert to the original correct form by re-inserting the colon (and typing M-q to reformat if you wish).
Our next rule, for VP, needs a verb, an optional object noun phrase, and the possibility of any number of prepositional phrases, including none at all. We express this by means of the Kleene star, *. On a new line type:
VP --> V
(NP)
PP*.
This gives the desired pattern of categories, but we also need some schemata to define the functional structures associated with these nodes. Since V is the head, and NP the object, the rule with the appropriate category-schemata pairs should read:
VP --> V: ^=!;
(NP: (^ OBJ)=!
(! CASE)=ACC)
PP*: ! $ (^ ADJUNCT).
Add the appropriate schemata to each category in the rule and save the file. Note that you can omit the semi-colon after the schemata for the NP and PP since the parentheses and final period are sufficient for XLE to infer where the schemata end. Also note that the schemata after the PP* applies to each of the zero or more PPs that may occur, with ! instantiated differently for each PP.
Finally, type in a rule for simple noun phrases. The determiner and head both contribute all their features to the f-structure of the whole phrase, so they should each have an ^=! schema. Relying on the convention that this schema is inferred by default if ! is not mentioned on a category, the rule can be written without any functional annotations at all:
NP --> (D)
N.
Caution: Be consistent in use of case when you type in categories and symbol designators. DET is not the same as Det to XLE and Case is not the same as CASE. If you have one of these in a rule and the other in a lexical entry, XLE will assume they are different categories and an analysis will fail for what may seem like a mysterious reason.
Now you have written a few grammar rules. A list of rules can be obtained from the LFG menu bar option (with only three rules you can see them all at once, but this is convenient for large grammars):
LFG
Start a *new* XLE process
Start an XLE process in *XLE* buffer or switch to existing one
Rules, templates, lexicon menus
Write menu contents to a file
Compare two XLE runs, report changes regarding which strings parse
Compare two XLE runs, full report
Display comments from current file
Display comments from .lfg files referenced in config information
Display comments from .lfg files in current directory
LFG
Choose the "Rules, templates, lexicon menus" option. This will ask you whether you want:
(toy-eng.lfg)
*Rescan*
TOY ENGLISH Rules
TOY ENGLISH Lexicon
TOY ENGLISH Rule macros
TOY ENGLISH Templates
(toy-eng.lfg)
Choose the "TOY ENGLISH Rules" option (there are not yet any macros or templates):
(TOY ENGLISH Rules)
NP
S
VP
(TOY ENGLISH Rules)
Chose "VP" and your cursor will move to the beginning of the VP rule.
If you only want to see the content of a rule, you can use "print-rule". Type "help print-rule" in the Tcl shell for more details.
Suppose you write a rule (for example: NP2-->AP NP.) and later decide you don't want it after all. You can delete a rule by deleting the text of the rule, saving the file (C-x C-s) and then restarting XLE.
To install the rules, an XLE process must be started with the grammar containing the rules in question. This can be done via the menu bar. Under LFG there is:
LFG
Start a *new* XLE process
Start an XLE process in *XLE* buffer or switch to existing one
Rules, templates, lexicon menus
Write menu contents to a file
Compare two XLE runs, report changes regarding which strings parse
Compare two XLE runs, full report
Display comments from current file
Display comments from .lfg files referenced in config information
Display comments from .lfg files in current directory
LFG
Choose "Start a *new* XLE process" which will switch the buffer to an XLE one with roughly the following information:
XLE loaded from xle. XLEPATH = /project/xle/solaris. Copyright (c) 2002-2004 by the Palo Alto Research Center. Copyright (c) 1993-2001 by the Xerox Corporation. All rights reserved. This software is made available AS IS, and PARC and the Xerox Corporation make no warranty about the software, its performance or its conformity to any specification. XLE release of Oct 13, 2004 10:02. Type 'help' for more information. /project/xle/solaris/site.tcl loaded. %
At this point XLE is running, but there is no parser. That is, your grammar is not installed. To do this, on the line with the %, which will be the line where the cursor is, type:
create-parser toy-eng.lfg
Alternatively, from the XLE menu:
XLE
Restart XLE
Start a *new* XLE process in another window
Create a parser
Create a generator
Parse a testfile
Generate from file
XLE
choose the "Create a parser" option. And when prompted in the echo area mini-buffer, type:
toy-eng.lfg
Followed by a carriage return. XLE will respond by loading the grammar and displaying the following message:
% create-parser toy-eng.lfg loading toy-eng.lfg... grammar has 12 rules with 9 states, 9 arcs, and 9 disjuncts Morph transducer files relative to /project/xle/solaris/bin/ 0.02 CPU seconds toy-eng.lfg loaded Grammar last modified on Jan 06, 2003 10:52. (Chart)4dc2b8 %
Whenever you wish to install a new rule, you must restart XLE using the "Restart" option under the XLE window and then create the parser again.
Lexical entries are similar to rules in terms of punctuation, installation, visiting, and editing. There are also corresponding menus: each lexicon window has an LFG menu.
Before you can use your rules to analyze a sentence, you have to define a few words---a toy lexicon.
Here is the implicit template for the lexicon:
word Category1 Morphcode1 Schemata1;
Category2 Morphcode2 Schemata2;
Etc.
Morphcodes determine whether or not a word uses the XLE morphology. If the morphcode is a star (*), the XLE morphology is not used — i.e., the word only matches tokens literally. If it is anything other than a star (normally, XLE), the XLE morphology is used — i.e., the word matches morphemes that come out of the XLE morphology. (See the morphology section for more information.) The schemata in lexical entries are identical in form and interpretation to the schemata that appear in c-structure rules, although they are not preceded by a colon.
Begin the TOY ENGLISH lexicon by entering the definition for walk. That is, go to the TOY ENGLISH LEXICON (1.0) section of the file and enter the word walk, the category V, the morphcode *, and the schema:
walk V * (^ PRED)='WALK<(^ SUBJ)>'.
The quote marks enclose the semantic form, as in pencil-and-paper entries. This form indicates that the predicate WALK takes one grammatical argument, a subject (SUBJ). The predicate in a semantic form must be a designator in the f-description language, usually a symbol without internal spaces. So if you wish to wax more descriptive, you can separate the words in the predicate with hyphens (for example, you might use KEEP-TABS for the idiomatic sense of keep). Like rules, lexical entries end with a period. As with rules, lexical items can be formatted by using M-q. Install the entry by saving the file (C-x C-s). Unlike rules, lexical entries are automatically installed and so you do not have to restart XLE after adding a new lexical item; saving the file containing the lexical item is enough.
Again as with rules, the dashes are supplied by the system to mark the end of a set (in this case only one) of lexical entries in a single version/language.
Notice that the word walk is entered in lower-case, as it would appear in ordinary text. When analyzing words in an input sentence, XLE first attempts to match lexicon headings against the characters just as they appear in the input. What happens when it appears in another form, such as with a capital letter, depends on the morphological analyzer used with XLE. XLE takes the sequence of characters up to the next white-space as the spelling of the lexical entry.
Of course walk can also be used as a noun. To express this alternative, add an entry for walk as a noun before the final period, using a semi-colon to separate the new entry from the pre-existing one:
walk V * (^ PRED)='WALK<(^ SUBJ)>';
N * (^ PRED)='WALK'.
Here too, the semi-colon ends a category specification. In rules, a sequence of categories means that they all must appear in the c-structure in that order. In lexical entries, a sequence of categories may be thought of as a disjunction since each indicates a possible interpretation of a homophonous word. The parser will try out each interpretation independently. Note that this is the only way that you can express a disjunction of lexical categories in XLE; the following specification, with the disjunction brackets around the categories and morphcodes, does not work:
walk { V * (^ PRED)='WALK<(^ SUBJ)>'
|N * (^ PRED) = 'WALK'}.
When you type M-q in a lexical entry, XLE checks the format and punctuation of your definition to see if it makes sense. If you have made, for example, a punctuation error that results in an ill-formed or nonsensical definition, XLE will indicate that through the formatting just as it does for errors in the notation of rules.
It is easier to write lexical entries (and rules as well) if you use an existing entry as a starting point and edit an old one into a new one by replacing selected elements of the starting entry with something new of the same type. Copy the entry for walk and edit it into one for girl by deleting the text from the V category to the semicolon, changing the word walk to girl and also changing the predicate WALK to GIRL. Then save the file. The result will look like this:
girl N * (^ PRED) = 'GIRL'.
Now let's consider a transitive verb. Edit the verb definition of walk into kick by copying the lexical entry for walk and then replacing walk with kick, adding in an (^ OBJ) and deleting the N part of the entry. Here's the result:
kick V * (^ PRED)='KICK<(^ SUBJ)(^ OBJ)>'.
This is a verb which can also be used without an object, as in Horses sometimes kick. It might seem natural to express this fact by surrounding (^ OBJ) with brackets or parentheses to indicate optionality, but XLE does not accept this notation. Instead, you must disjoin two largely similar schemata as follows:
{ (^ PRED)='KICK<(^ SUBJ)(^ OBJ)>'
|(^ PRED)='KICK<(^ SUBJ)>'}
Note also that disjunction only applies at the level of equations; you can't say
(^ PRED) = { 'KICK<(^ SUBJ)(^ OBJ)>;'
|'KICK<(^ SUBJ)>'}
Our inventory of words will need a determiner, so enter a definition for the:
the D * (^ DEF)=+.
The lexical entry the is not a predicate in our toy lexicon, just an entity that has a positive value for the feature of definiteness (however that might be interpreted).
You have perhaps entered enough rules and lexical entries to analyze (or parse) the girl walks. Create an XLE buffer via the LFG menu and then create a parser by typing:
create-parser toy-eng.lfg
At the % type (the string to be parsed must be enclosed by double quotes or by curly brackets):
parse {the girl walks}
XLE attempts to analyze the words of the string and apply the grammar to them. In this case it cannot find a lexical entry for walks. XLE will respond with:
% parse {the girls walks}
parsing {the girl walks}
(re)Indexing lexicon section ( TOY ENGLISH ) for parse
Chart unconnected because of unknown words
Word possibly causing problem: walks
0 solutions, 0.89 CPU seconds, 0 subtrees
0
%
XLE will also display a morphology window which shows how it attempted to analyze the sentence. The problem is that XLE doesn't know that walks is the third person singular form of walk because we haven't specified any morphology for the current analysis environment. This is usually taken care of by a morphological analyzer. But for the moment, let's enter walks as a separate word. Copy the entry for walk in toy-eng.lfg. Now append an s on walk and, at the same time, you might as well give the schemata for person, number, and tense:
walks V * (^ PRED)='WALK<(^ SUBJ)>'
(^ SUBJ NUM)=SG
(^ SUBJ PERS)=3
(^ TENSE)=PRES;
N * (^ PRED)='WALK'
(^ NUM)=PL.
Save the file to install this entry and then try the parse again. In this case, you do not need to restart XLE, since you have only changed the lexicon. XLE notices that you have changed the lexicon and automatically re-installs it. This only works for lexical entries: if you change a file with other types of grammatical resources, then XLE will warn you that the grammar has changed.
When you try it with the newly installed definition for walks, the analysis succeeds. The number of solutions and the time it took to perform the analysis, are displayed in the prompt window and are also recorded for future reference at the end of the sentence:
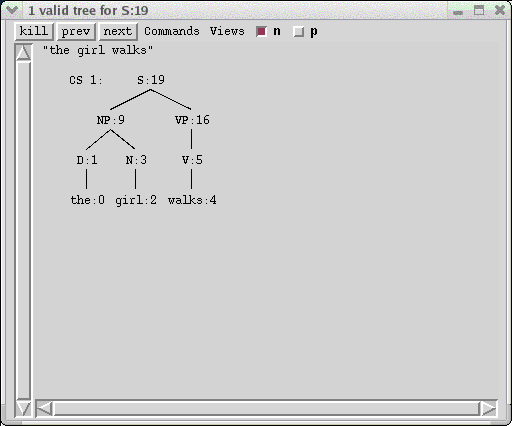
% parse "the girl walks"
parsing {the girl walks}
(re)Indexing lexicon section ( TOY ENGLISH ) for parse
1 solutions, 0.1 CPU seconds, 8 subtrees
1
%
The system also records the number of subtrees, a measure of the number of steps XLE required to perform all the constituent structure computations. The c-structure and f-structure for the sentence also appear in their windows:
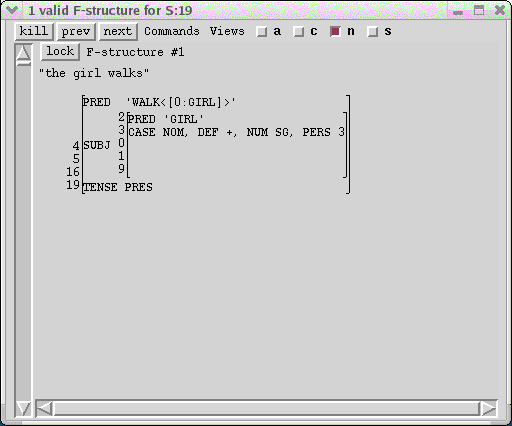
With the middle mouse botton, click on D in the tree. The information provided at that node from the lexical entry and the equations on the node appears in the f-structure window.
As with the rules (and templates), a given lexical item can be chosen via the LFG menu option "Rules, templates, lexicon menus" which will now read:
(toy-eng.lfg)
*Rescan*
TOY ENGLISH Lexicon
TOY ENGLISH Rule macros
TOY ENGLISH Rules
TOY ENGLISH Templates
(toy-eng.lfg)
If you choose the "Lexicon" option you will then get a list of the lexical items in alphabetical order:
(TOY ENGLISH lexicon)
girl
kick
the
walk
walks
(TOY ENGLISH lexicon)
Clicking on a lexical item will move your cursor to that lexical item's entry.
The menu is of all lexical entries either currently active or defined in the selected version/language. If there are too many of them to fit easily in a single menu, the words will appear in multiple, partially overlapping menus that can be accessed by moving the cursor rightward onto the desired menu and then onto the lexical item.
If you only want to see the content of a lexical entry, then you can use the Tcl command print-lex-entry. Type help print-lex-entry in the Tcl shell for more details.
Putting schemata in the lexical entry for an affix factors those specifications out from all the word-forms that take that affix, and thus enables morphologically-related generalizations to be stated across broad classes of lexical items. XLE provides another way of expressing functional generalizations that are not obviously correlated with inflectional morphology. You can incorporate a collection of schemata into the definition of a named template, and then use the name of the template in place of those schemata in lexical entries or in c-structure rules. The specifications of individual lexical entries or rules can thus be streamlined, with the template definition representing the common properties that are shared by all the items that mention (or invoke) it.
To see how a template can express a generalization, consider the requirement shared by all English count nouns that their singular forms must appear with an explicit determiner. This requirement could be imposed in the lexical entry for girl by adding the following constraints:
(^ NUM)=SG (^ DEF)
to produce the extended entry:
girl N * (^ PRED)='GIRL'
{ (^ NUM)=SG
(^ DEF)
|(^ NUM)=PL}.
The new disjunction asserts that either the number is singular and some value exists for the feature DEF, or the number is plural. This same disjunction could also appear in the definitions of all other common nouns, but instead we incorporate it into the definition of a CN (for Count Noun) template. A template is defined and edited in the template section of the grammar file. In the template section, following TOY ENGLISH TEMPLATES (1.0), type in the following definition for the CN template:
CN = (^ NUM)=SG
(^ DEF).
As with rules, you must save the file and then restart XLE to install the template. Also M-q can be used to format the template, just as with rules and lexical items.
Save toy-eng.lfg and restart XLE. This definition of the CN template has now been entered into XLE's internal database, and it has also been activated so that it can be invoked in various lexical entries. The template was activated because when XLE earlier constructed the default TOY ENGLISH configuration, it anticipated that you would eventually define and want to make use of some templates. As you can see by looking at the configuration display, it is specified in the TEMPLATES part of the configuration.
The lexical entry for girl now can be simplified by making use of the CN template. Go to the lexical entry for girl and add @CN in place of the explicit disjunction. The entry will now be shortened to
girl N * (^ PRED)='GIRL'
@CN.
This shows that a template can be invoked in a position where an ordinary schema might otherwise appear simply by writing the name of the template preceded by the character @. Other common nouns can also share the schemata included in the template definition. By defining boy like girl, for example, you will obtain the following lexical entry:
boy N * (^ PRED)='BOY'
@CN.
Calls to the template @CN can also be added to the N entry of walk, ensuring that all of the count nouns in the lexicon call the same template. The advantage of this approach is that if at some point in the future you want to extend or modify how common nouns behave, you can edit just the definition of the template and the change will affect all of the lexical entries that invoke it.
The template mechanism can be used to simplify somewhat further the entries for all common nouns. In addition to the determiner/number interaction already expressed in the CN template, all common nouns also include a schema defining their particular PRED. By providing the semantic predicate as a parameter of the common-noun template, you can also factor out the details of even the PRED specification from individual entries. To see how this works, go back to the definition of the CN template.
You need to indicate that the predicate is going to be provided as a parameter at each invocation of the template, and that the given predicate is then to appear in the semantic-form of a PRED schema. You must specify a parameter-name, say P, to stand for the predicate that will be supplied each time, and use that in a generalized PRED schema. You specify that P is the parameter name by including it in parentheses between the template name and the following equal sign. You then add the generalized PRED schema to the body of the template definition. The result is the following definition:
CN(P) = (^ PRED)='P'
(^ NUM)=SG
(^ DEF).
Having installed this definition, you must then change all of the common-noun entries so that they no longer specify their idiosyncratic PRED schema and instead supply their particular predicate as an argument to the CN template. The entries for girl and boy simplify to:
girl N * @(CN GIRL). boy N * @(CN BOY).
Note that when a parameterized template is invoked, the template name and the values for its parameters are both enclosed in parentheses after the @.
A template can be invoked in any position where an ordinary schema might otherwise appear. Templates can thus be invoked in lexical entries, as you have just seen, as well as from the functional annotations on c-structure rules. It is also possible for the invocation of one template to appear in the definition of another one, so that the effect of the first one is included whenever the second one is invoked. The pattern of inter-template references typically forms a hierarchy that can encode and organize families of linguistic generalizations. Templates in XLE can thus play the same explanatory role that inheritance of typed feature structures plays in Head-Driven Phrase Structure Grammar (Pollard & Sag, 1994). This is true even though templates are purely abbreviatory devices and do not require the deep mathematical analysis that type inheritance seems to call for.
You can define a few more templates with more interesting reference relationships. Begin by defining templates just for the PRED schemata of intransitive and transitive verbs and another template that invokes these to provide for verbs that are optionally transitive:
INTRANS(P) = (^ PRED)='P<(^ SUBJ)>'.
TRANS(P) = (^ PRED)='P<(^ SUBJ)(^ OBJ)>'.
OPTTRANS(P) = {@(INTRANS P)|@(TRANS P)}.
After saving the file to install these, choose the "Rules, Templates, Lexicon menus" option from the LFG menu. A menu of the currently active templates will pop up:
(TOY ENGLISH Templates) CN INTRANS OPTTRANS TRANS (TOY ENGLISHTtemplates)
You have now learned how to enter a grammar into the system and how to apply it in the analysis of strings typed into XLE. It is likely for a simple grammar that all the rules are correct and that they are compatible with the lexical entries and morphological rules you have specified. But that is less likely to be true as your grammars become more complex and cover a larger fragment of a natural language. XLE's grammar-debugging facilities can help you explore the linguistic consequences of your grammatical formulations so that you can detect and correct both conceptual errors and errors of specification. You will be better able to see how to do this by using a grammar slightly less limited than TOY ENGLISH in toy-eng.lfg. The file demo-eng.lfg, which is supplied along with the XLE software, contains a grammar more suitable for experimenting with the system's testing and debugging facilities. This grammar contains rules, lexical entries, and some templates. It also contains two configurations, including a DEMO ENGLISH configuration.
Bring up demo-eng.lfg in an emacs buffer. The file is stored where this file and the other XLE documentation html files are stored; you can copy demo-eng.lfg to your own directory if you wish. Start an XLE process via the LFG menu and create a parser with:
create-parser demo-eng.lfg
XLE will respond with a message that it is loading the grammar. The cursor will appear on the prompt.
% create-parser demo-eng.lfg loading demo-eng.lfg... grammar has 16 rules with 16 states, 15 arcs, and 15 disjuncts (re)Indexing lexicon section ( DEMO ENGLISH ) for parse Morph transducer files relative to /project/xle/solaris/bin/ 0.05 CPU seconds demo-eng.lfg loaded Grammar last modified on Jan 06, 2003 11:34. (Chart)4f79f8 %
The strings you then type into XLE window will be analyzed with respect to the new grammar.
Request a parse by typing the following string into XLE:
% parse {the girl devours a banana}
At this point the parser uses the rules, lexicon, and morphology of the DEMO ENGLISH configuration to analyze the sentence. Since the top-level parsing category for this analysis defaults to the category S, which is defined in the DEMO ENGLISH configuration as the root category of this grammar, you do not need to prefix the sentence with S:. The parsing category determines which rules to apply in a particular analysis (only those necessary to build constituents of that type) and what kind of structures to show in the c-structure window. You will see below how to override the default root category when you temporarily want to focus on the rules for other types of constituents.
The analysis of the sentence is completed quickly, and summary information indicating the number of f-structure solutions, the computing time, and the number of subtrees is printed under the sentence in the XLE window and the cursor is placed at the prompt for the next sentence to be parsed:
% parse {the girl devours a banana}
parsing {the girl devours a banana}
1 solutions, 0.01 CPU seconds, 13 subtrees
1
%
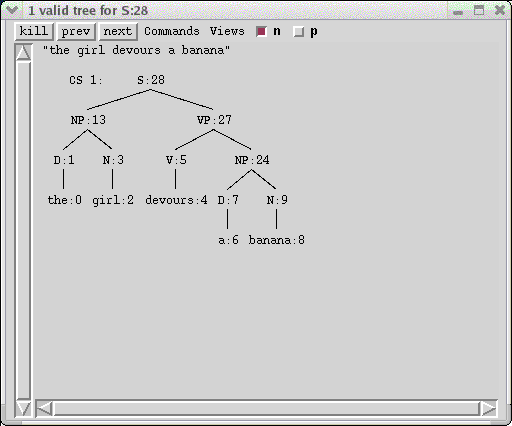
Grammatical structures discovered for the sentence appear in the C-structure and F-structure windows.
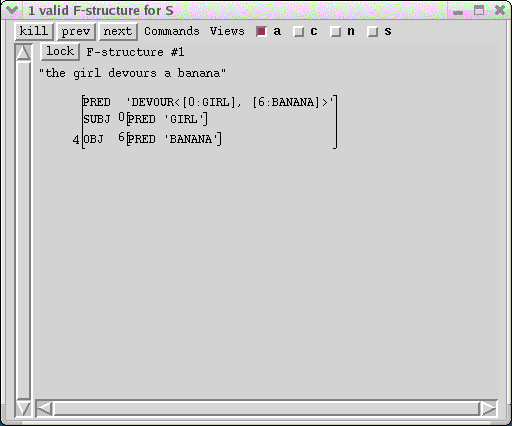
The title bar of the C-Structure window tells you how many valid trees that the sentence had. For this simple sentence there is only one c-structure whose f-structure constraints have at least one valid solution. The single valid c-structure is displayed in the window:
There is also only a single f-structure for this c-structure, shown in the F-structure windows:
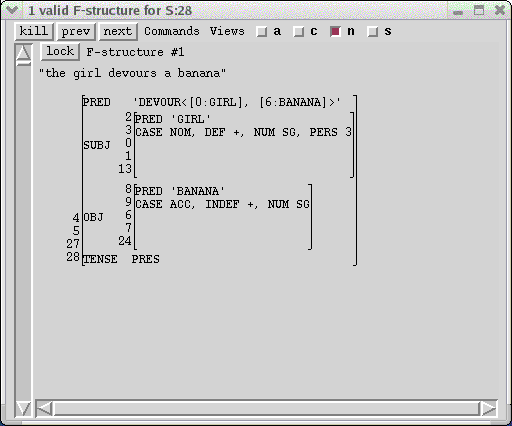
The title-bar of the F-structure window also indicates the number of solutions displayed in the window and the overall number of f-structures. For this example, the single solution meets all the grammaticality conditions and is displayed in the window.
The f-structure is displayed as an attribute-value matrix in standard LFG format, with the brackets annotated by identifying indices. The arguments in the semantic-form value of the PRED attribute are abbreviated representations for the full f-structures with the same index number shown below. Thus, [0:GIRL] shows that the first argument of DEVOUR is f-structure 0, which is also the value of the SUBJ attribute. GIRL, the relation in the semantic-form PRED of f-structure 0, is included in the abbreviation to make it easier to interpret. In this display the symbol-valued features are shown on a single line separated by commas so that more information can be shown in a given amount of screen space.
The numeric indices play the role of the variables f1, f2, etc. that are sometimes used to annotate f-structures in published presentations of LFG. These indices serve to correlate the units of the f-structure with the c-structure nodes they correspond to. Each c-structure node that the parser discovers is assigned a unique node-number, whether or not it forms part of a valid S c-structure. The default display is to have the node numbers displayed. Clicking on the "node numbers" menu item under the Views menu at the top of the c-structure window will cause the tree to be redrawn without visible node-numbers (this can be helpful with very large trees):
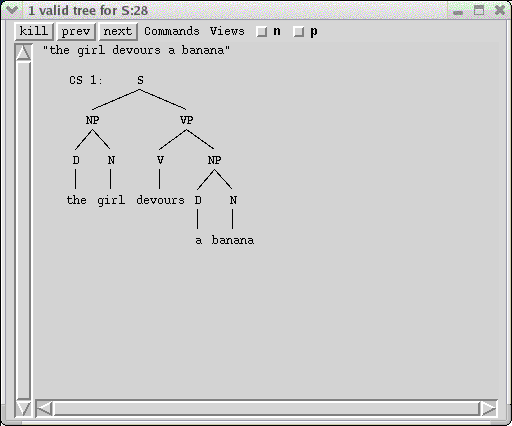
You can click again on the "node numbers" item to turn back on the node-number display. Typing "n" in the window has the same effect, as shown by the accelerator at the right of the menu item. Note that the check box "n" next to the Views menu is now turned off. These check boxes help you to keep track of what is being displayed.
Comparing these node-numbers with the indices on the f-structure, it is easy to see that the outermost f-structure corresponds not only to the root S node, but also to the VP and V nodes. This reflects the many-to-one nature of the c-structure to f-structure correspondence, and also formalizes the intuition that the V is head of the VP and the VP is head of the sentence.
The displays in the C-Structure and F-Structure windows give access to additional information about the analysis. Whenever you click on a button with the right mouse button, a description of that button will appear in the XLE window. Whenever you click on a node with the right mouse button, a description of that node will appear as a menu. For example, when you click on the S node with the right mouse button, XLE states:
In this section, you will go through some of the more common features used by the grammar writer. Additional documentation on the windows can be found in the XLE interface documentation.
By selecting nonterminal nodes lower in the tree, you can examine information from smaller parts of the sentence. If you select a preterminal lexical category you can focus just on lexical template expansions. Selecting a terminal node (a word) does not show the instantiated lexical schemata, since instantiating them only trivially modifies the lexical information. So, when you click the middle button on the V node, for example, the f-structure window displays the functional description associated with that node:
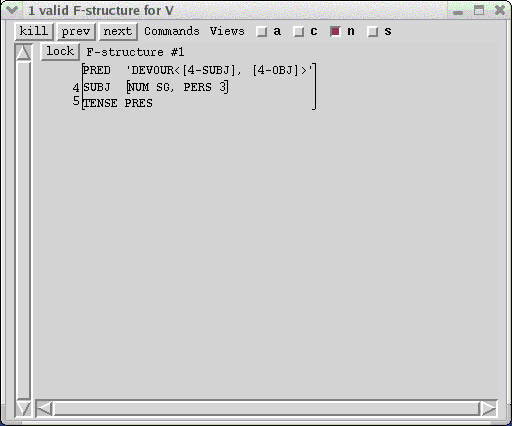
This resembles the f-structure for the dominating S node but some details of the SUBJ and OBJ f-structures are missing. The PERS and NUM are included in the SUBJ, because they are supplied from the verbal inflection, but the PRED does not appear because it is not defined within the V subtree, and no information is present for the OBJ. The solution is not considered incomplete, however, because it is still possible for the predicate to be filled higher up. If you middle-click on the root S, the original outermost f-structure will be displayed, with the SUBJ completed.
This is a good point to explore some of the other features of the f-structure window. Click on the "constraints" menu item under the Views menu in the f-structure window. This will display the constraints which the f-structure must satisfy to be (ultimately) well formed. In this case, for example, both the SUBJ and the OBJ will need a PRED value:
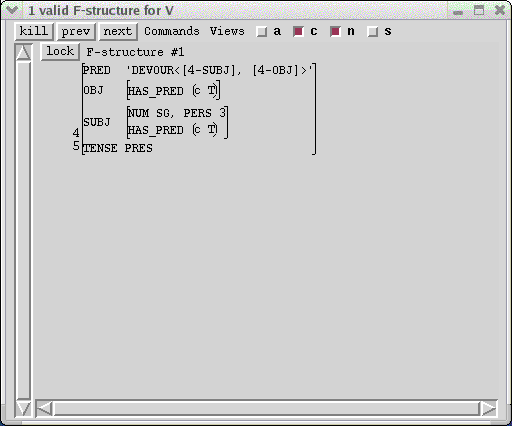
Click on the "constraints" menu item again with the left mouse button to toggle it off; the constraints will no longer be displayed. Now redisplay the f-structure of the entire sentence by clicking on the S node in the c-structure window with the middle mouse button. In the f-structure window, click on the "abbreviate attributes" menu item under the Views menu and the "node numbers" menu item with the left mouse button. This will display only the PRED features and their values; this can be extremely useful for viewing large f-structures to determine their basic structure.
In general, there can be a large number of alternative trees over a given string, some of which are valid and some of which are invalid. For the intial c-structure display, XLE chooses one particular tree from the set of valid tress (if there are any), and that tree's f-structure solutions are shown in the f-structure window.
Enter the sentence:
the girl in the park with the telescope devours a banana
This sentence has two different c-structures, depending on how the prepositional phrases are attached.
The title of the c-structure display reports that there are two valid c-structures, but only one is displayed. If you want to examine the other tree, you can click the left button or the "next" button on the c-structure window title bar. Clicking on the "prev" button will redisplay the first tree.
You may need to scroll the window horizontally, using the bottom scroll-bar, to see all of the tree (or toggle the node numbers to off). You can click on its nodes with the middle mouse button to see its associated f-structure displays. If a sentence has both valid and invalid trees (this one does not), the invalid trees will be displayed after all of the valid ones and can be viewed by clicking the next button until the invalid trees are displayed.
There is another way to view the trees which is to look at the subtrees at a given node. This is convenient when hunting for a particular tree when there are a large number of solutions. You can get the next subtree of a node by clicking on it with the left mouse button. You can get the previous subtree via shift-left mouse button. If there are no more trees, the button will flash. For example, if you click on the subject NP of CS 1 with the left mouse button, the next subtree will be displayed; this corresponds to the structure in CS 2. To get back to the structure in CS 1, click on the subject NP with shift-left mouse button.
Whenever you click on a node in a tree with the middle button while the Control key is held down, the constraints associated with that node will be printed in the Constraints Window. The constraints will come from the lexicon if the node is a pre-terminal node, and otherwise they will come from a rule. The constraints are the base constraints that are obtained when all of the templates have been expanded. Constraints that are filtered from the grammar before instantiation are printed with a comment after them. For instance, if an =c constraint is globally incomplete, it will printed with a "GLOBALLY INCOMPLETE" comment following it. Similarly if an optimality constraint has a NOGOOD mark, then it will be printed with a "NOGOOD OPTIMALITY MARK" printed after it. Since these constraints aren't instantiated they won't appear in the f-structure window (even among the invalid f-structures) and so the only way to see them is to use the Constraints Window.
The solutions displayed in the F-structure window represent not only the f-structures themselves but also, by virtue of the node numbers, the c-structure to f-structure mapping.
The solutions in the F-structure window also have several display features, most of which were described above. As with the c-structure window, the valid and then invalid f-structures can be scrolled through using the "next" and "prev" buttons. Node numbers, constraints, and abbreviated attributes were described above: they toggle the display of the node numbers, the display of constraints, and the display which provided just PRED values.
XLE uses special techniques (see, for example, Maxwell and Kaplan, 1993) to identify the nodes in a tree at which particular conjunction-sets in the disjunctive normal form become unsatisfiable, and it tries to confine the presentation of unsatisfactory solutions just to the nodes where they first go bad. These strategies also help in making the linguistic representations more comprehensible, but sometimes the results are surprising. To illustrate one effect, enter the sentence:
the sheep devoured a banana
This produces a single c-structure with two f-structure solutions corresponding to whether sheep is singular or plural due to the lexical entry (make sure that you are not abbreviating attributes at this point):
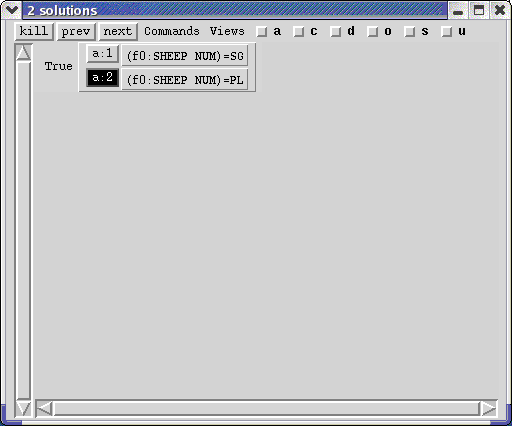
sheep N * { @(N-SG SHEEP)
|@(N-PL SHEEP)}.
If you middle-click on the N dominating sheep, you will see the disjunction reflected in two f-structure solutions which are displayed one at a time. There is a more convenient way to determine the difference between the two valid f-structures: the fschartchoices window and the fschart window.
The f-structure chart windows are used to display two different views of a packed representation of all of the valid solutions. One window indexes the solutions by constraints. The result is an f-structure that is annotated with choices to show where alternatives are possible. The other window indexes the solutions by choices. The result is a tree of choices with their corresponding constraints. The choices in both windows are active. When you click on a choice, then a solution corresponding to that choice is displayed in the tree window and the f-structure window.
The f-structure chart window indexes the packed solutions by their constraints, so that each constraint appears once in an f-structure annotated by all of the choices where that constraint holds:
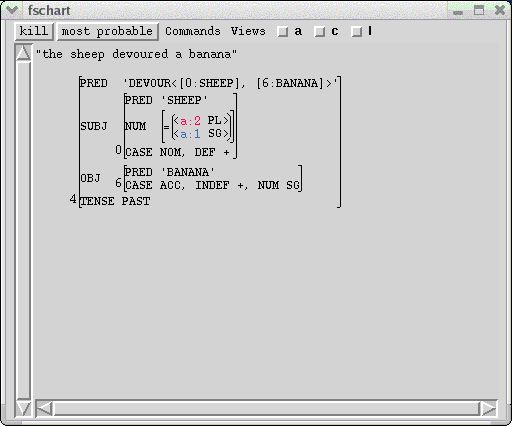
By default, this window appears at the upper right of the display. There are three menu items under the Views menu that control how the f-structure is displayed. The "abbreviate attributes" menu item determines whether or not only PREDs are displayed. The "constraints" menu item determines whether or not negated and sub-c constraints are included in the display. Finally, the "linear" menu item changes the display into a line of tokens with corresponding f-structures.
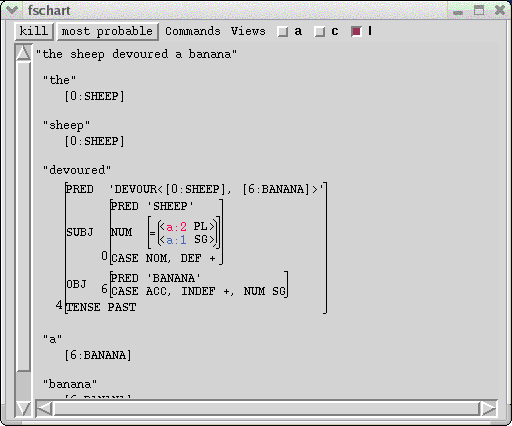
The f-structure chart choices window indexes the packed solutions by the alternative choices. By default, this window appears at the lower right of the display. Choices are labeled a:1, a:2, a:3, ... b:1, b:2, b:3, etc.
The choices that belong to the same disjunction have the same alphabetic string as a prefix. At the left of each disjunction is its context. Top level disjunctions are given the True context. Embedded disjunctions are given the choice that they are embedded under. By default, only f-structure constraints are displayed. If you want to see c-structure constraints, click on the "subtree" menu item under the Views menu.
When the "nested" menu item is selected, then each disjunction will be nested within the choice that define its context under the constraints that are particular to that context.
If you click on a choice in the fschartchoices window with the left mouse button, the c- and f-structures corresponding to that choice will be displayed. In addition, that choice will be highlighted in the fschart display and appear in red (instead of blue) in the fschart window.
Now parse the sentence:
a sheep devoured the banana
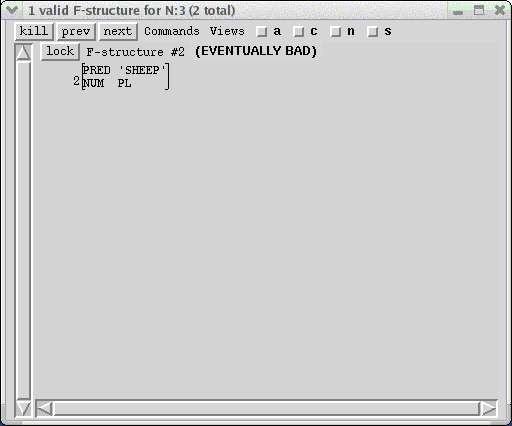
In this case there is only one valid f-structure because the determiner a is not compatible with a plural noun phrase. When you click on the subject NP node to see the solutions for the f-description at that node, only the SG solution appears. The plural specification on the noun is incompatible with the singular feature of the indefinite article. That inconsistency is detected as the article and noun are being combined, and solutions for all conjunction-sets containing that inconsistency are not presented. However, if you click on the N node above sheep with the middle mouse button, the f-structure window will state that there are two f-structures, but only one is valid. To view the invalid one, simply click on the "next" button. The resultant F-structure #2 is marked (EVENTUALLY BAD):
If the grammar defines additional projection structures to be in correspondence with the f-structure, then they will be indicated by a button in the f-structure window, even if they are a projection off of the c-structure. Clicking on this button will open an additional window with the projection in it. The DEMO ENGLISH grammar defines a sigma projection which is discussed later.
So far you have only parsed sentences for which the grammar can construct c-structure trees. If the grammar cannot produce a c-structure tree, either because it does not know a lexical item or because it cannot fit the known lexical items into a tree, then a morphology window appears showing how the morphology attempted to analyze the string. Try parsing:
a sheep devours in the park
Since the grammar cannot parse post verbal PPs, no c-structure is produced and instead the following morphology appears:
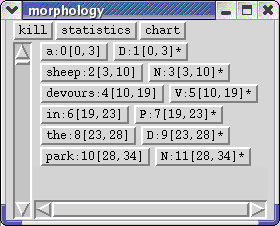
The best way to debug this sort of problem is to try parsing subparts of the sentence, e.g.
parse {PP: in the park}
parse {VP: devours in the park}
until you find out where the problem is.
If the problem is that the morphology does not recognize a word, a message to this effect will appear in the XLE window, in addition to the morphology window appearing:
% parse {a sheep in the garden devours a banana}
parsing {a sheep in the garden devours a banana}
Chart unconnected because of unknown words
Word possibly causing problem: garden
0 solutions, 0.01 CPU seconds, 0 subtrees
0
%
Well-formed constituent structures are filtered through the functional well-formedness conditions. By default, the system automatically displays one c-structure tree for which the functional description of the root node is consistent and is satisfied by at least one complete and coherent f-structure. If none of the c-structures are valid in this way, then one of the invalid trees is chosen for display. Thus, if you analyze the string
a boys saw the girl in the park
you will see the following c-structure window:
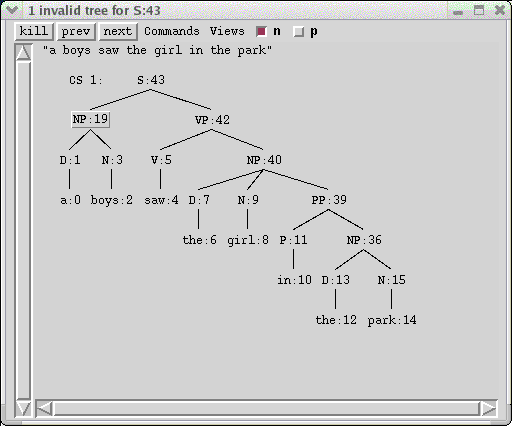
The box around the NP node indicates that it is the lowest node in the tree where the f-description becomes unsatisfactory. That is, the D and N subtrees both have satisfiable f-descriptions, but when the f-descriptions of those two nodes are combined together according to the assertions in the NP rule, the resulting formula no longer has well-formed solutions. This being the case, XLE does not bother to compute or solve the f-description for the higher S node, and the f-structure window is left completely empty to signal that nothing has been computed.
The boxed nodes in the tree along with the empty f-structure window may be enough information to confirm that your grammar correctly classifies unacceptable strings as ungrammatical. In some cases, however, it may be important to examine the analysis results in more detail to make sure that the bad strings are bad for the right reasons. A detailed inspection of invalid results may also be useful in locating errors in your grammar or lexicon that mark as ungrammatical a string that you expect to be accepted. Although XLE usually does not display them, invalid solutions are available for inspection after all of the good solutions. If there are no good solutions, then XLE displays bad solutions in the following order: unoptimal first, then incomplete, then inconsistent, then various combinations of unoptimal, incomplete, and inconsistent. For each bad solution, XLE gives some indication of why the solution is bad.
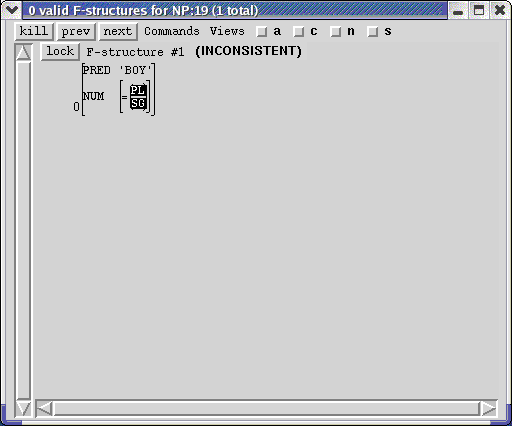
For example, suppose you wanted to see more of the details of the boxed NP's f-structure analysis. If you click on that NP with the middle button, the F-structure Window changes to indicate that there is one solution to the f-description at that node but that it is inconsistent. The faulty structure is displayed with the inconsistency highlighted black:
If you enter
the girl sleeps the telescope
you will see only an invalid tree in the C-structure Window. Again, the boxes around the VP's indicate indicate where the solutions have gone bad: The functional requirements for all nodes below the VP's are satisfactory, but there was no way of combining the solutions for their daughters to make valid solutions for the VP's. Middle-click on VP to display its f-structures. The f-structure window indicates that there is one solution, but it is incoherent. Notice that OBJ has been highlighted to show that it is the ungoverned attribute:
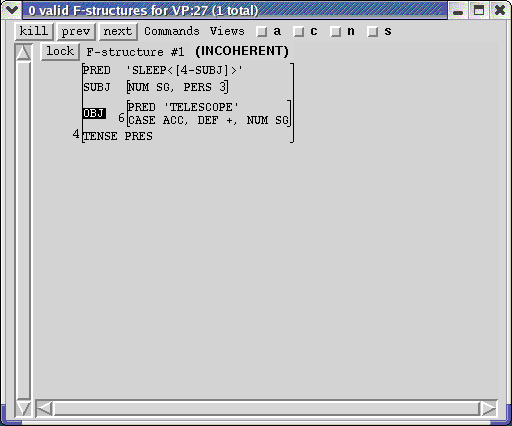
Middle-clicking on the S node provides no interesting functional information. It is above the boxed VP's, and these are already known to be bad in irredeemable ways. XLE does not bother to propagate the incorrect results into higher structures, to avoid excessive computation.
The Coherence Condition as enforced by XLE is slightly different than the condition defined originally by Kaplan and Bresnan (1982). According to the original definition, an f-structure is regarded as incoherent if a governable grammatical function is not sanctioned by a local predicate. Experience has suggested a refinement to this definition, and XLE marks a governable function as incoherent if a local predicate exists and it does not sanction the function. For example, this allows an f-structure corresponding to a prepositional phrase to have an OBJ even though the preposition itself serves as a semantically vacuous case-marker.
Now parse:
the girl devours
This sentence has no solution because it is incomplete, i.e. it is missing an object. Usually incompleteness is detected at the top-level S, when it is known that there is no more information to be had. However, in this case the sentence is marked bad at the V constituent. XLE conducted a global analysis and determined that the attribute OBJ is not assigned by any of the schemata instantiated from the grammar rules or lexical entries for this tree, implying that the verb's subcategorization frame can never be satisfied, and that it is therefore pointless to solve any equations at the VP level or above. This global analysis permits better localization of the source of the difficulty---it enables the box to be drawn at the V instead of the S. It also allows XLE to prune incompletenesses early, producing a substantial improvement in performance. If you click on V, you can see the bad solution in the f-structure window.
The f-structure ontology as proposed by Kaplan and Bresnan (1982) did not include a `bottom' element to represent the complete absence of information about the value of an attribute. F-descriptions containing statements of the form (^ SUBJ)=(^ OBJ) would give rise to unacceptable solutions if there were no other specification for either the SUBJ or the OBJ. The f-description would be indeterminate, since there was no single smallest element to serve as the common value. However, XLE does include a bottom element in the f-structure subsumption lattice, and that element provides for unique minimal solutions for f-descriptions of this sort. If an attribute has bottom as its value, then neither the attribute nor the value is shown in the f-structure display, just as if no assertion about the attribute had been made. This arrangement is particularly convenient when relating elements of different projections: a general statement can be made to map f-structure adjuncts to semantic-structure modifiers, for example, and the f-description will be acceptable even when the particular f-structure has no adjunct.
Expressions of functional uncertainty can be used in XLE to encode constraints on various sorts of nonlocal f-structure dependencies. The following NP rule, for example, uses this mechanism to form topicalised structures:
S --> (NP: (^ XCOMP* {OBJ|OBJ2})=!
(^ TOPIC)=!)
NP: (^ SUBJ)=!
(! CASE)=NOM;
{ VP
| VPaux}.
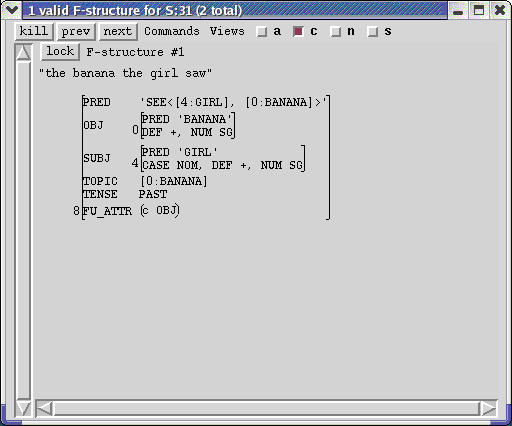
The functional uncertainty equation on the TOPIC NP identifies that NP's f-structure with the OBJ or OBJ2, possibly of a nested XCOMP. Parse the sentence:
the banana the girl saw
Notice that the OBJ f-structure is identical to that of the TOPIC. If you click on the constraints button, then the path that the functional uncertainty took will be indicated by the value of FU_ATTR relation, which is constrained to be OBJ in this case.
XLE allows the grammar writer to define projections other than the phi (c-structure to f-structure) correspondence. New projections are usually used to describe major sub-systems of linguistic theory. For instance, there could be a sigma projection to handle the semantics, a rho projection to encode selectional restrictions, and a delta projection for a discourse structure. Other uses for projections have been proposed, such as a tau projection that defines the translation of an f-structure into some other language (Kaplan et al., 1989; Kaplan and Wedekind, 1993).
To see an example of how projections can be used, restart XLE with:
create-parser demo-eng-sigma.lfg
This will install a new configuration, activating new rules and templates. You can examine this configuration by looking at the top of demo-eng-sigma.lfg which contains the SIGDEMO ENGLISH configuration:
SIGDEMO ENGLISH CONFIG (1.0) ROOTCAT ROOT. FILES demo-eng.lfg. LEXENTRIES (DEMO ENGLISH) (SIGDEMO ENGLISH). RULES (DEMO ENGLISH) (SIGDEMO ENGLISH). TEMPLATES (DEMO ENGLISH) (SIGDEMO ENGLISH). GOVERNABLERELATIONS SUBJ OBJ OBJ2 COMP XCOMP OBL OBL-?+. SEMANTICFUNCTIONS ADJUNCT TOPIC FOCUS POSS STANDARD. NONDISTRIBUTIVES NUM PERS CONJ-FORM. EPSILON e. OPTIMALITYORDER NOGOOD. ----
You can compare this to the configuration in demo-eng.lfg:
DEMO ENGLISH CONFIG (1.0) ROOTCAT S. FILES . LEXENTRIES (DEMO ENGLISH). RULES (DEMO ENGLISH). TEMPLATES (DEMO ENGLISH). GOVERNABLERELATIONS SUBJ OBJ OBJ2 COMP XCOMP OBL OBL-?+. SEMANTICFUNCTIONS ADJUNCT TOPIC FOCUS POSS STANDARD. NONDISTRIBUTIVES NUM PERS CONJ-FORM. EPSILON e. OPTIMALITYORDER NOGOOD. ----
Note that SIGDEMO ENGLISH uses the lexicon (LEXENTRIES), rules (RULES), and templates (TEMPLATES) of DEMO ENGLISH. However, it also provides its own lexical entries, rules and templates which will override those in DEMO ENGLISH if they identically named. That is, not only can SIGDEMO ENGLISH provide additional rules, such as the ROOT rule which allows for punctuation, but it also allows the grammar writer to write new versions of rules, such as the VP rule which allows optional post object PPs. Note that each section of the grammar starts with a specification of which part it is. So, the SIGDEMO ENGLISH template section begins with:
SIGDEMO ENGLISH TEMPLATES (1.0)
Once a grammar has become relatively large, it is often convenient to divide these sections into different files. For example, there might be one file called demo-eng-lex.lfg which contains the lexical items for DEMO ENGLISH and another called sigdemo-eng-lex.lfg which contains the lexical items for SIGDEMO ENGLISH. These are called in the configuration by FILES; the order of the files reflects the order in which they override one another, with the last one overriding all the previous ones. For example:
FILES demo-eng-lex.lfg
sigdemo-eng-lex.lfg
Now analyze the sentence:
the girl devours a banana
The c-structure window and the f-structure window have essentially the same information as before, although the c-structure now starts with the category ROOT. However, if you now click on the s::* button in in the f-structure window with the left mouse button, a new window will open with a primitive semantic structure for the sentence:
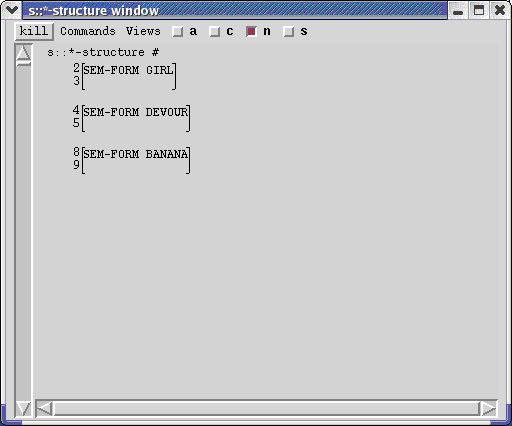
The numerical indexes in this display identify the f-structure elements that the sigma projection maps to the associated semantic structure units. The semantic structure window is very similar to the f-structure window.
If there is more than one projection defined for f-structures, then more than one button will appear in the f-structure window. Each button will have the letter prefix of that projection. For example, the s::* button is for the semantic projection and o::* for the optimality projection (this is predefined and will appear if optimality marks are used in the grammar).
Currently, one thing makes debugging with other projections tricky, however: An f-structure solution will sometimes be marked incomplete or inconsistent when there is nothing wrong with the f-structure itself. Instead, one of its projections is incomplete or inconsistent, and XLE does not distinguish between the different projections when determining that a solution is bad.
We usually think in terms of parsing sentences, and S is thus commonly specified as the ROOT component of the configuration. Even though S is the root category for the grammar as a whole, you may wish to focus on some other category, say NP, while you are developing and debugging its rules and lexical entries. This means you can test the NP subgrammar without typing in complete sentences, and XLE will not spend as much time exploring grammatical possibilities that are irrelevant to your current concerns. Also, XLE will automatically display in the C-Structure Window any trees spanning the string that are labeled with the current parse category.
You can use any category in the active grammar as the current parsing category. There are two ways to designate the category to be parsed. This first is to type that category as a prefix to the string to be parsed. XLE will parse the string as that category no matter what the current default parse category is set to.
% parse {NP: the girl}
parsing {NP: the girl}
1 solutions, 0.03 CPU seconds, 4 subtrees
1
% parse {PP: in the park}
parsing {PP: in the park}
1 solutions, 0.05 CPU seconds, 7 subtrees
1
%
In the configuration file, it is possible to define the default parsing category via the value of ROOTCAT. In DEMO ENGLISH, this is S. So, if you parse a string with the DEMO ENGLISH parser and do not overtly specify a category, it will try to parse it as an S. In SIGDEMO ENGLISH, the default category is ROOT. So, if you parse a string with the SIGDEMO ENGLISH parser and do not overtly specify a category, it will try to parse it as a ROOT.
This section walks you through the creation of a set of transfer rules. It uses demo-eng.lfg as a basis. The transfer rules that we will create map the f-structures of the grammar onto new f-structures. (It is possible to rewrite the f-structures into other formats, but we do not go into that here.) Note that the top part of the main transfer documentation provides a detailed description of how transfer rules work, especially as regards f-structure facts, and a sample set of translation rules.
Create a file called demo-eng-xfr.pl. The first line of this file should read:
"PRS (1.0)"
This first line indicates the format that the rules are in. Note that it is technically a comment, since anything that appears in quotes is a comment, just as in grammar and lexicon files. In order for transfer to correctly interpret the rules, there cannot be any other comment line before this one.
The second line should read:
grammar = demo-eng-xfr.
This gives a unique name to the grammar. We will not be making crucial use of this here but there are situations in which multiple grammars are used, in which case they must be named.
Our first rule will rewrite the f-structure feature NUM to NUMBER. To do this, add the following rule to demo-eng-xfr.pl:
NUM(%Fstr,%Num) ==> NUMBER(%Fstr,%Num).
The left-hand side of the rule looks for a feature NUM of an f-structure %Fstr; this feature has a value %Num. The % indicates a variable name. Multiple instances of a variable in a rule must refer to the same fact (e.g., f-structure or f-structure feature/value). The ==> indicates that the rule is obligatory; ?=> indicates an optional rule, as we will see below.
To see how the rule works, we need to start up the transfer system and load the grammar and the transfer rules. To do this, create a shell in emacs (M-x shell) and type 'xle' at the prompt to start XLE. Then run the following commands:
% create-transfer % create-parser demo-eng.lfg % load-transfer-rules demo-eng-xfr.pl
These commands will call transfer, create a parser from the relevant grammar, and then load your transfer rule file. As with XLE in general, you can use path names if your grammar or transfer rule file is not in the same directory that you are launching XLE from, e.g.
% create-parser /home/users/thking/demo/demo-eng.lfg
Now parse a sentence in the usual manner:
% parse {a girl walks}
The usual four XLE windows will pop up. Under "Commands" in the f-structure (lower left) window, there will be a number of new options, as shown below:
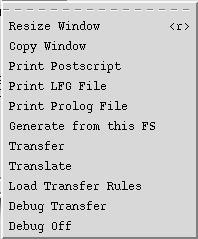
These are documented in more detail in the XLE transfer documentation. First choose "Transfer". This will result in the result of the transfer rules appearing at the XLE command line:
Output Predicates:
[
% Choices:
[],
% Equivalences:
[],
% Equalities:
[],
% Facts:
[
cf(1, 'CASE'(var(1),'NOM')),
cf(1, 'INDEF'(var(1),+)),
cf(1, 'NUMBER'(var(1),'SG')),
cf(1, 'PERS'(var(1),3)),
cf(1, 'PRED'(var(1),'GIRL')),
cf(1, 'PRED'(var(0),'WALK')),
cf(1, 'SUBJ'(var(0),var(1))),
cf(1, 'TENSE'(var(0),'PRES')),
cf(1, arg(var(0),1,var(1))),
cf(1, lex_id(var(1),0)),
cf(1, lex_id(var(0),1))
]]
This is a prolog format representation of the output, similar to the prolog format representation of the f-structure that is produced by XLE using commands such as print-fs-as-prolog. To see the output more graphically, under "Commands" choose "Translate". The first time you do this, there will be a bunch of warning messages generated in XLE which you can safely ignore; they occur because demo-eng.lfg does not have a generator version. Instead, look at the two windows that XLE has popped up. The left hand one is the input to the transfer rules; its title bar should say "F-structure window for Source". The right hand one is the output of the transfer rules; its title bar should say "F-structure window for Transfer Result". If you compare these, you will notice that they are virtually identical except that NUM SG of GIRL is NUMBER SG in the transfer result window.
Our next rule will provide a CASE feature for nouns that do not already have CASE. To do this, we need a way to identify nouns. In the case of the grammar being used here, we can assume that everything with a number feature is a noun. Remember that our previous rule rewrote NUM to NUMBER. The current rule must therefore refer to NUMBER since transfer rules are ordered. Once nouns can be identified, we need to make sure that they do not already have a case feature. This is done by prefixing the CASE feature with a minus sign (-) to form a negated pattern. In this rule, we choose ACC as the value to insert if there is no case already. Add the following rule to your file, making sure that it occurs after the NUM-NUMBER rule.
+NUMBER(%Fstr,%%), -CASE(%Fstr,%%) ==> CASE(%Fstr,ACC).
There are two additional things to notice about this rule. The plus sign (+) in front of the NUMBER feature means that it will not be consumed (i.e., will not to be deleted) by the rule. If we did not put in the +, then the NUMBER would disappear from the f-structure whenever the rule applied. We will see the + feature several more times in these rules. The second is the special variable %%. Variables beginning with %% are called anonymous variables; they are essentially wildcards that will match any value. In this case, NUMBER can be either SG or PL and the rule will apply regardless of which is found.
In order to get the new rule to load, you have to reload the transfer rules, just as you have to reload the grammar if you change the grammar rules or the templates. There are two ways to do this. One is to rerun the following command in the XLE window:
load_transfer_rules demo-eng-xfr.pl
The other is to choose "Load Transfer Rules" under "Commands" in the f-structure window. If you do this, a prompt will appear in the XLE window asking for the name of the rule file to load.
Enter name of rule file to be loaded:
>>
Type in demo-eng-xfr.pl and hit return and it should tell you that the rules have been loaded.
To see the output of the new rule, do:
parse {a banana a sheep devoured}
Note that the topicalized object a banana does not have a case feature and hence should trigger the rule. Before running the transfer, choose "Debug Transfer" under "Commands" in the f-structure window. Then choose "Translate" to see the resulting structure. In addition to NUM now being NUMBER for both noun phrases, the noun phrase for banana has CASE ACC. Note that sheep does not have CASE ACC because the -CASE(%Fstr,%%) blocked the rule from applying to an f-structure that already had case. If you look at the XLE window, you will notice that having turned on the debugging, there is information about which rules have applied:
============================================
Rule 1: NUM(%Fstr,%Num)
==>NUMBER(%Fstr,%Num)
File /home/users/thking/demo/demo-eng-xfr.pl, lines 3-3
Rule 1 matches: [4] NUM(var(1),SG) 1
--> 1
NUMBER(var(1),SG)
[5] NUM(var(2),SG) 1
--> 1
NUMBER(var(2),SG)
============================================
Rule 2: +(NUMBER(%Fstr,A)), -(CASE(%Fstr,B))
==>CASE(%Fstr,ACC)
File /home/users/thking/demo/demo-eng-xfr.pl, lines 4-4
Rule 2 matches: [+(19)] NUMBER(var(2),SG) 1
--> 1
CASE(var(2),ACC)
Transfer: 0.000 secs.
In this case, both rules applied: Rule 1 applied twice and Rule 2 applied once. Using debugging in this way can be very useful in tracking why a rule that you expected to apply did not.
Next we will write a slightly more complicated rule that looks for PP adjuncts and assigns them an ADJUNCT-TYPE PP. The rule looks as follows:
+ADJUNCT(%%,%AdjSet), +in_set(%Adj,%AdjSet), (+PRED(%Adj,IN) | +PRED(%Adj,WITH)) ==> ADJUNCT-TYPE(%Adj,PP).
Note that all of the facts on the left-hand side of the rule are preceded by +. This means that they will not be deleted when the rule applies. There are two new parts of the rule. The first is the in_set feature. This feature is what takes you through the elements of a set (which appear within curly brackets) in an f-structure. The in_set notation can be slightly confusing because the arguments are ordered so that the first argument is the set element, while the second is the set itself. Using the names in the rule, this would correspond to an f-structure like:
%%[ ADJUNCT %AdjSet{ %Adj[ ] } ]
The second new bit of notation is the disjunction indicated by parentheses: ( | ). This rule stipulates that the PRED of the ADJUNCT element must be either IN or WITH. If this is the case, then ADJUNCT-TYPE PP is assigned to it. To see this, reload the rules and then run the following in the XLE window:
parse {a girl walks in the park}
Then choose Translate and look at the resulting transfered structure. The PP adjunct now has an ADJUNCT-TYPE.
As with writing XLE grammars, the XLE transfer system allows you to define templates and macros for commonly used combinations of facts. We will now add a template and macro and calls to them in our rules. Lets say that we want to have a rule that adds an ANIM feature to animate nouns. We could do this with:
+PRED(%Fstr,BOY) ==> ANIM(%Fstr,+).
+PRED(%Fstr,GIRL) ==> ANIM(%Fstr,+).
+PRED(%Fstr,SHEEP) ==> ANIM(%Fstr,+).
This is tedious and prone to error. If we needed to change the type of ANIM feature that was assigned, we would have to do so in three places. Instead, we can define a template which has as its argument the value of the PRED:
ANIM(%Pred) ::
+PRED(%Fstr,%Pred) ==> ANIM(%Fstr,+).
The template has a name (ANIM) and the definition follows the double colon (::). We can then call the template for each predicate that we want it to apply to:
@ANIM(BOY).
@ANIM(GIRL).
@ANIM(SHEEP).
As in the XLE grammars, templates are called with an @. Add the template definition and calls to your grammar. It is important that the definition appear before the calls to it. Reload the rules, parse:
parse {a girl walks}
and "Translate" this f-structure. The transfered f-structure should have an ANIM + feature for GIRL.
Macros are similar to templates except that where templates contain rule applications, macros contain sets of facts only. For example, we could define a macro that looked for nouns by looking for f-structures with both a number and a person feature. As with templates, macros have names. However, they are followed by := instead of a double colon. Our noun identifying macro would be:
NOUN(%Fstr) :=
+NUMBER(%Fstr,%%), +PERS(%Fstr,%%).
and we could call it from any rules that need to identify nouns (note that the macro definition must appear before the call to it). For example, we could have a rule that puts in a TYPE NOUN feature for all nominal f-structures.
@NOUN(%Fstr) ==> TYPE(%Fstr, NOUN).
As with templates, the call to a macro is preceded by an @. The rule will expand the macro so that the rule will have the NUMBER and PERS requirements defined there. Add the macro and rule call to your grammar, reload the rules, parse:
parse {a girl walks}
and Translate this f-structure. The transfered f-structure should have an TYPE NOUN feature (not all nouns will end up with a TYPE NOUN feature because some nouns in this grammar do not have a PERS featuare which is needed by the NOUN macro). Note that many of our previous rules have also applied: NUM has become NUMBER and GIRL has ANIM +.
Our final transfer rule is an optional rule that passivizes transitive verbs. To do this, we want to find f-structures with an object and a subject. The subject will become the oblique agent with a by feature. The object will become the subject. Finally, a PASSIVE + feature is introduced. Add the following rule to your grammar:
SUBJ(%Fstr,%Subj), OBJ(%Fstr,%Obj)
?=> SUBJ(%Fstr,%Obj), OBL-AG(%Fstr,%Subj), PFORM(%Subj,BY), PASSIVE(%Fstr,+).
In this rule, the SUBJ and OBJ are not preceded by + signs because they will be deleted by the rule application (and replaced by OBL-AG and a new SUBJ). The ?=> indicates that the rule is optional, unlike all the previous rules that used the ==> and were hence obligatory. The original object %Obj is rewritten as the new SUBJ. The original subject %Subj is rewritten as the OBL-AG; it is also assigned a PFORM BY feature. Finally, the main f-structure %Fstr is assigned a PASSIVE + feature. Add this rule to your grammar, reload the rules, parse:
parse {the boys devoured a banana}
"Translate" this structure. Since this is an optional rule, the choice space has been split in the "Transfer Result" window. You should see a:1 and a:2 choices depending on whether the rule applied (a:1) or not (a:2). To see one of the solutions, left click on the choice in the window. For example, click on the a:1. A new window should pop up entitled "F-structures for Slected transfer result". You can left click on a:2 to see the other result.
This walkthough has provided a basic introduction to the XLE transfer system. To see other ways in which rules can be written and other ways in which to run the transfer system (e.g., batch mode), consult the transfer manual.
Halvorsen, Per-Kristian and Ronald M. Kaplan. 1988. Projections and semantic description in Lexical-Functional Grammar. In Proceedings of the International Conference on Fifth Generation Computer Systems (FGCS-88), pages 1116--1122, Tokyo, Japan, November. Reprinted in Mary Dalrymple, Ronald M. Kaplan, John Maxwell, and Annie Zaenen, eds., Formal Issues in Lexical-Functional Grammar, 279--292. Stanford: Center for the Study of Language and Information. 1995.
Kaplan, Ronald M. and Joan Bresnan. 1982. Lexical-Functional Grammar: A formal system for grammatical representation. In Joan Bresnan, editor, The Mental Representation of Grammatical Relations. The MIT Press, Cambridge, MA, pages 173--281. Reprinted in Mary Dalrymple, Ronald M. Kaplan, John Maxwell, and Annie Zaenen, eds., Formal Issues in Lexical-Functional Grammar, 29--130. Stanford: Center for the Study of Language and Information. 1995.
Kaplan, Ronald M. 1987. Three seductions of computational psycholinguistics. In Peter Whitelock, Mary McGee Wood, Harold L. Somers, Rod Johnson, and Paul Bennett, editors, Linguistic Theory and Computer Applications. Academic Press, London, pages 149--181. Also: CCL/UMIST Report No. 86.2: Alvey/ICL Workshop on Linguistic Theory and Computer Applications: Transcripts of Presentations and Discussions. Center for Computational Linguistics, University of Manchester, Institute of Science and Technology, Manchester. Reprinted in Mary Dalrymple, Ronald M. Kaplan, John Maxwell, and Annie Zaenen, eds., Formal Issues in Lexical-Functional Grammar, 337--367. Stanford: Center for the Study of Language and Information. 1995.
Kaplan, Ronald M. and Annie Zaenen. 1989. Long-distance dependencies, constituent structure, and functional uncertainty. In Mark Baltin and Anthony Kroch, editors, Alternative Conceptions of Phrase Structure. Chicago University Press, Chicago, pages 17--42. Reprinted in Mary Dalrymple, Ronald M. Kaplan, John Maxwell, and Annie Zaenen, eds., Formal Issues in Lexical-Functional Grammar, 137--165. Stanford: Center for the Study of Language and Information. 1995.
Kaplan, Ronald M., Klaus Netter, Jurgen Wedekind, and Annie Zaenen. 1989. Translation by structural correspondences. In Proceedings of the 4th Meeting of the European Association for Computational Linguistics, pages 272--281, University of Manchester. Reprinted in Mary Dalrymple, Ronald M. Kaplan, John Maxwell, and Annie Zaenen, eds., Formal Issues in Lexical-Functional Grammar, 311--329. Stanford: Center for the Study of Language and Information. 1995.
Kaplan, Ronald M. and Jurgen Wedekind. 1993. Restriction and correspondence-based translation. In Proceedings of the 6th Conference of the Association for Computational Linguistics European Chapter, pages 193--202, Utrecht University.
Maxwell, III, John T. and Ronald M. Kaplan. 1993. The interface between phrasal and functional constraints. Computational Linguistics, 19(4):571--590. Reprinted in Mary Dalrymple, Ronald M. Kaplan, John Maxwell, and Annie Zaenen, eds., Formal Issues in Lexical-Functional Grammar, 403--429. Stanford: Center for the Study of Language and Information. 1995.
Pollard, Carl and Ivan A. Sag. 1994. Head-Driven Phrase Structure Grammar. The University of Chicago Press, Chicago.